
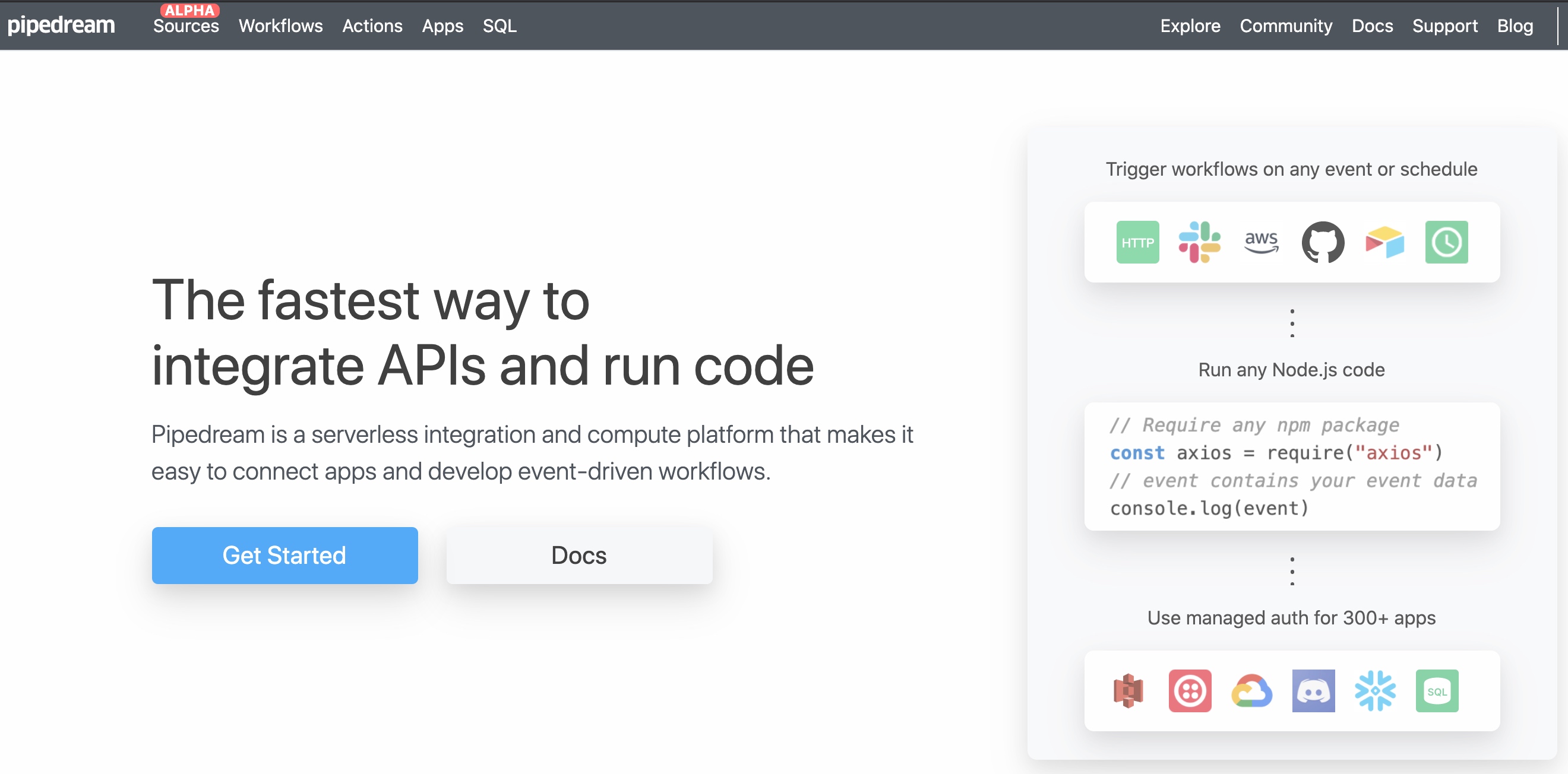
今天在搜索引擎上发现了两个国外的网站,可以做到不需要编程,只需要简单几个步骤就能完成推特、Github、亚马逊Aws等数据收集并将数据导入Dropbox,谷歌文档等网盘中,他们是如何做到的呢?
简单两个步骤
使用了其中的两个产品,就发现其实也很简单,就是两步,第一步配置需要收集的数据源,比如Twitter认证,需要的数据API;第二步配置需要保存的数据位置,比如谷歌文档中某个文档的id;再设定运行的策略,就形成了一个可以收集数据、保存数据、按照指定策略运行的工作流,这样不需要编程也能获取特定数据。
平台的价值
本质上来说,这个网站价值点就是工作流与策略运行;
数据的两端,一个是数据端,提供数据的网站有成熟的API供用户使用,一个是保存端,网盘服务商有保存文档数据api,任意一端缺乏,都有办法解决。
比如缺乏数据端,网站也提供了可以喂数据API,缺乏保存端,网址可以调用任意API接口,让用户保存数据。
所以看到这里大家也能明白,除了工作流,这个网站自然也能运行自定义的代码,不需要代码不代表不支持代码,比如在保存数据前需要做的数据分析,自然要自定义代码来完成,其他更高级、自定义的玩法也需要自定义代码。
其他
这种无代码数据获取与保存的工作流,在中国已经有人在弄了,比如模版类数据抓取方案,平台提供一堆可以抓取数据的模版,用户配置完毕后,可以下载数据,或者将数据直接推送到特定网址,众多的采集器走的更远,模版都不需要了,任何网页都可以分析获取,不过国外的这家公司似乎正规点,毕竟用的还是网址公开的API完成。
写在最后
我把网址放在了下面,如果大家对这种不用编程获取数据、分析数据比较感兴趣的话,可以去看看。
http://www.pipedream.com; https://funnel.io/