
最近测试的一些 headless cms,安装、使用与数据获取,为 NextJS 构建内容前端做准备。
文章目录
选取标准
- 无头内容管理。
- 方便与nextjs 集成,很多厂商都能做到。
Sanity(sanity.io)
首先选择 sanity 做测试。
安装
从官网登录后,根据提示安装
npm create sanity@latest -- --template get-started --project dblle8hj --dataset production --provider google
下载、安装依赖完毕后,启动:pnpm dev,根据提示打开本地 studio,http://localhost:3333。
使用
内容结构体
本地打开的窗口是内容编辑器,而不是开发者工具。
在目录中的 schema 文件夹中,新建一个内容体的描述文档,news.ts,添加如何内容
export default {
name: 'news',
type: 'document',
title: 'News',
fields: [
{
name: 'title',
type: 'string',
title: '标题',
},
{
name: 'summary',
type: 'text',
title: '摘要',
},
{
name: 'content',
title: '详细内容',
type: 'array',
of: [
{
type: 'block',
},
{
type: 'image',
fields: [
{
type: 'text',
name: 'alt',
title: 'Alternative text',
description: `Some of your visitors cannot see images,
be they blind, color-blind, low-sighted;
alternative text is of great help for those
people that can rely on it to have a good idea of
what\'s on your page.`,
options: {
isHighlighted: true,
},
},
],
},
],
},
],
}
修改 schema 文件夹中的 index.ts,导出结构体。
import news from './news' export const schemaTypes = [news]
新建内容
编辑器(http://localhost:3333) 将自动刷新,依次点击 Desk/Content/News,编辑新内容,编辑完毕,点击 Publish,发送这份内容到 Sanity 的数据库中即可。
富文本的编辑器
官方说明文档,这里,根据 schema 中,字段类型需要为 array,在of 中提供多种编辑器组合,比如 block(富文本编辑器),image(添加图片等)。
API 获取结构体
点击 Vision,构建查询语句,QUERY中,输入:*[_type == "news"],点击 Fetch,右侧 RESULT 区域展现 API 获取到的数据。
上面演示的部分,news 的 content,是一部分富文本编辑+图片的模式,返回的数据中可以看到,他会将富文本部分,拆分成各种结构化的数据,而不是一整块的内容存储。这种处理方式是以前没见过的。
大概的查询方式,api 获取的结果也已经知道。
其他
- 拆分整个内容体结构,这个是以前没见过的。没有 wordpress 那么灵活。
- 本地化的编辑器,不太友好,还没研究如何将本地化的编辑器弄成局域网站点的形式。
- 本地化富文本编辑器相对简单,改变字体颜色等,需要添加额外的组件
npx sanity install @sanity/color-input,以及 schema 修改, - 在线服务,没有提供展示内容的模板,需要另外安装部署。
WordPress + WPGraphQL
WordPress 自带的 API
WordPress 自身也提供了 api 获取内容体,比如,https://blog.1kcode.cn/wp-json/wp/v2/posts?categories=17,https://blog.1kcode.cn/wp-json/wp/v2/categories ,只是输出的结构体很复杂,包含了所有的数据内容,比如 ld+json 中的内容,也需要权限。
WordPress rest api,官方说明
什么是 graphql
GraphQL 是一种 API 调用的规范,类似于其他接口,直接用 HTTP 方式,将查询内容体 POST 到服务器,不需要为不同的资源访问,使用不同的地址(比如 users对应 /users)等。
GraphQL 最大的优势是查询图状数据,在查询数据时用 GraphQL 描述一下要查询的这些边和顶点就行,不需要去改 API 实现,调用方获取更多的主动权,需要什么数据,在query 中描述清楚就行了,而不是调用多个接口去组合完成任务,新增、减少数据体,也不需要服务器再调整。
GraphQL 到底是什么?
不少博文在做 GraphQL,我们也来测试下。
WPGraphQL
WPGraphQL 是一个免费的开源 WordPress 插件,它为任何 WordPress 站点提供可扩展的 GraphQL Schema 和 API。
安装
管理后台搜索,安装插件,WPGraphQL。
使用
点击顶部入口GraphiQL IDE,进入编辑页面,构建查询语句。
在设置页面,可以设置认证后才能调用接口。
集成
下载使用最新版的nextjs,npx create-next-app@latest,使用示例工程中的 posts 查询功能,GraphQL Query Posts
查询顶级分类,并携带相应的posts:
query GetCategoryEdges {
categories {
nodes {
id
name
posts {
nodes {
id
title
date
excerpt
}
}
}
}
}
这里需要转变下思路,不是 rest api 模式,先找出所有分类,再根据分类id 去查询 posts,而是想要什么数据,直接写在 query 中就可以了。
fechAPI 中存在缓存,需要给 api.ts 中的fetchAPI 指定缓存的策略。
- GraphQL 在线编辑器
- 不一定需要WPGraphQL 自带的编辑器,外部的编辑器也是可以的。
- 查询时使用到的一些结构体描述,比如 category 查询时可以使用哪些字段排序,TermObjectsConnectionOrderbyEnum 描述
WPGraphQL 的解释文档,为啥需要 ObjectsConnection,这里也有很多API 的讲解,比如菜单、类别,tag 数据获取等。
查询次数过多,不太稳定。
其他
- 查询带参数,参数需要在 query 后面的方法中做声明。
query GetPersonById($id:Int!) { person(id: $id) { name(includeSurname: true) } }
Strapi(strapi.io)
最后测试另一个 headless cms,strapi,从官方文档开始。
安装
命令行启动第一个工程,npx create-strapi-app@latest strapi-project --quickstart。执行完毕后,自动打开登录界面。
这里可以看到,数据保存在本地,去掉参数 –quickstart,可以在安装时,选择哪种数据库,以及数据库的连接方式与数据库选择。
使用
注册第一个管理员账号。简单注册完毕,开始创建第一个 content type,这点比 sanity 要方便,不需要手工去编辑文件,图形化界面操作。并且提供了引导步骤。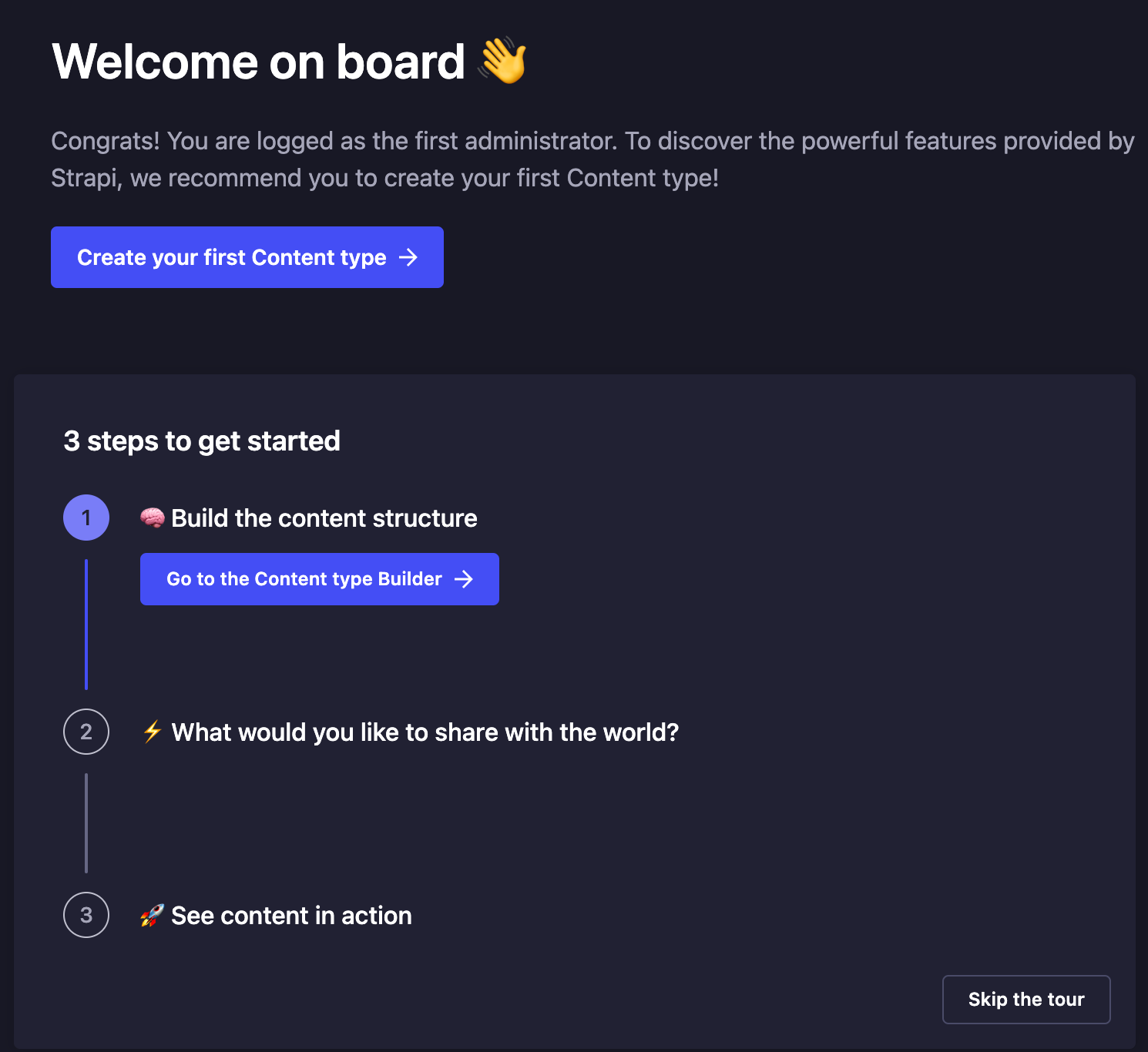
第一步,添加一个新的 COLLECTION TYPE,也就是一些内容本身字段信息。保存完毕后自动重启。
第二步,重启完毕,进入 Content Manager,创建第一篇文章。
第三步,根据引导页,跳转到 api 管理页面,创建一个用于 api 访问的 token。8c09610629fe7d61a3f205057a5478d785b186541f1807711061f0c8218fdd9c1eeb677772f93fe43a4a48600da4a7604af23df2ace224d91f616443f07a45f3b3061871c6ae7942f340d5ddaa2b35d63c77cbd55c33e573f967fcdeb182c03157e23ce26e4ab835c6d5d54d3033b6898817b88445100d76e5f29a2806ce3646
添加富文本编辑器?
添加第一个富文本字段,需要用到插件,根据提示跳转到插件管理器,找到 CKEDIT5,点击添加后,将插件命令复制到了剪贴板,需要手工安装。
命令行切换到工程目录,执行复制的安装命令,yarn add @ckeditor/strapi-plugin-ckeditor,执行完毕后,系统自动重启。
再次进入 Content-Type Builder,给刚才的博客内容体添加一个新的字段,类型为 Rich text,保存完毕,自动重启。
进入Content Manager,编辑时,可以看到一个新的字段编辑器,可以满足基本的操作要求,还支持 Markdown 格式。
API 数据获取
界面上有提供内容获取的方式说明,但没有提供内置的数据获取方式,需要第三方工具测试 API,直接使用 curl 测试。curl -H "Authorization: bearer 8c09610629fe7d61a3f205057a5478d785b186541f1807711061f0c8218fdd9c1eeb677772f93fe43a4a48600da4a7604af23df2ace224d91f616443f07a45f3b3061871c6ae7942f340d5ddaa2b35d63c77cbd55c33e573f967fcdeb182c03157e23ce26e4ab835c6d5d54d3033b6898817b88445100d76e5f29a2806ce3646" http://localhost:1337/api/posts
返回的数据格式中,是 Markdown 格式的原始数据,不像 Sanity 那样,使用标签格式化了数据,简单一些。db 中保存的也是 markdown 数据。
API 说明文档
其他
- 可以完全本地运行,数据保存在本地,付费的云端服务,不需要操心部署,直接使用即可。
- 展示内容的模板,需要另外签出工程修改,不出意外,需要使用 ReactMarkdown。
- 很多功能需要安装插件支持。
- 付费服务支持全球 CDN。
Directus(directus.io)
看到一些网友推荐过,测试下这个自由度最高的无头内容管理系统。
安装
可以直接在官网点击 Get Started,直接在 Directus Cloud 上创建工程使用,99 一个月。先选择免费的 self-hosted 社区版本,看看情况。
不像前面两个 cms,直接展示 cli 命令行,在文档的最后找到self-hosted 支持,两种方式,docker 与 cli 创建工程。选择本地创建,使用看看。
- 执行命令,npm install directus;
- 目录初始化,npx directus init,选择数据库为简单的 sqlite,完成询问信息,管理员账号密码设置等。
- 启动 npx directus start
使用
根据提示,复制地址到浏览器中访问,开始使用 Directus,http://0.0.0.0:8055,输入刚才设置的账号和密码,登录。
创建集合
也就是创建一个表,包含哪些字段,输入post,也提供了一些字段给参考。直接提供了富文本的支持,WYSIWYG 类型。可以定制化的内容非常。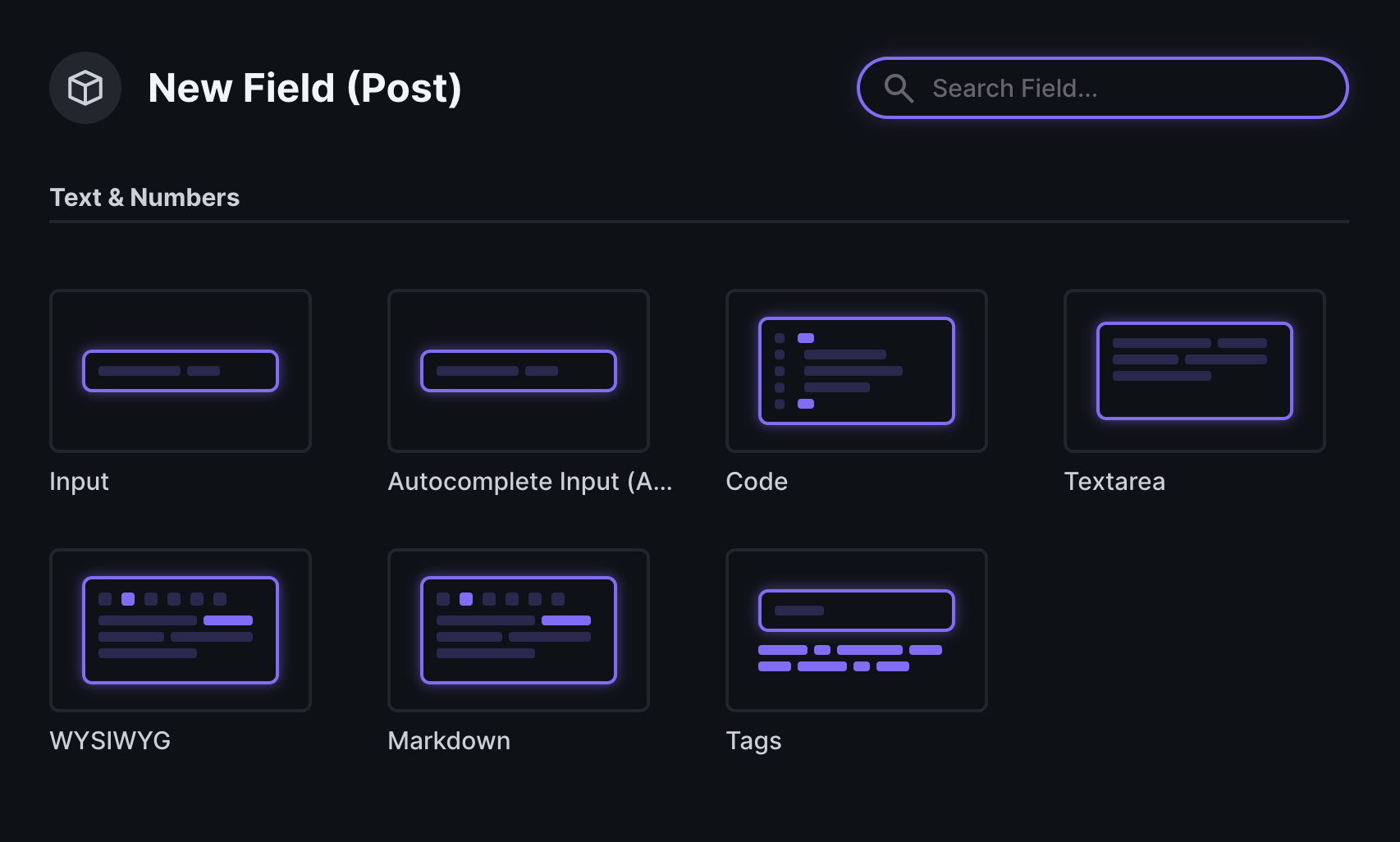
创建内容
选择左侧按钮的第一个,进入内容管理,创建第一篇内容。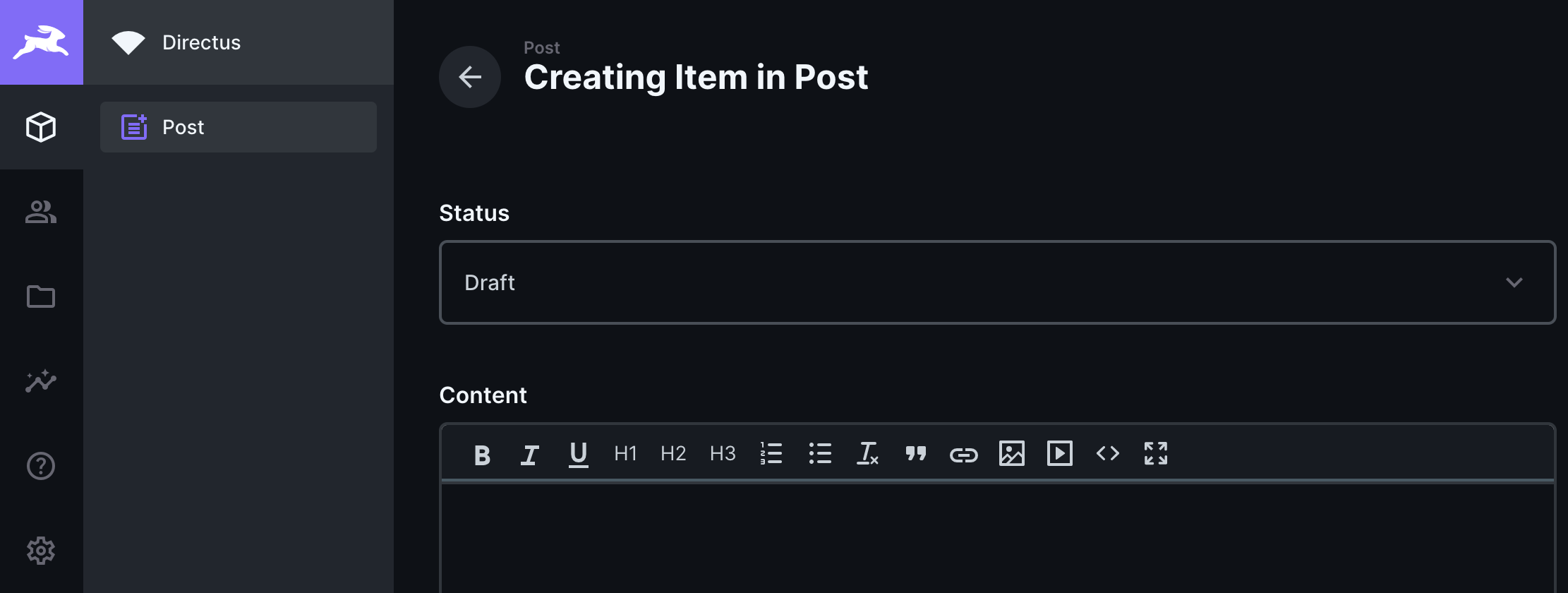
所见即所得的编辑器还能直接修改源码,添加 class 等
提供导入和导出的功能。
内容权限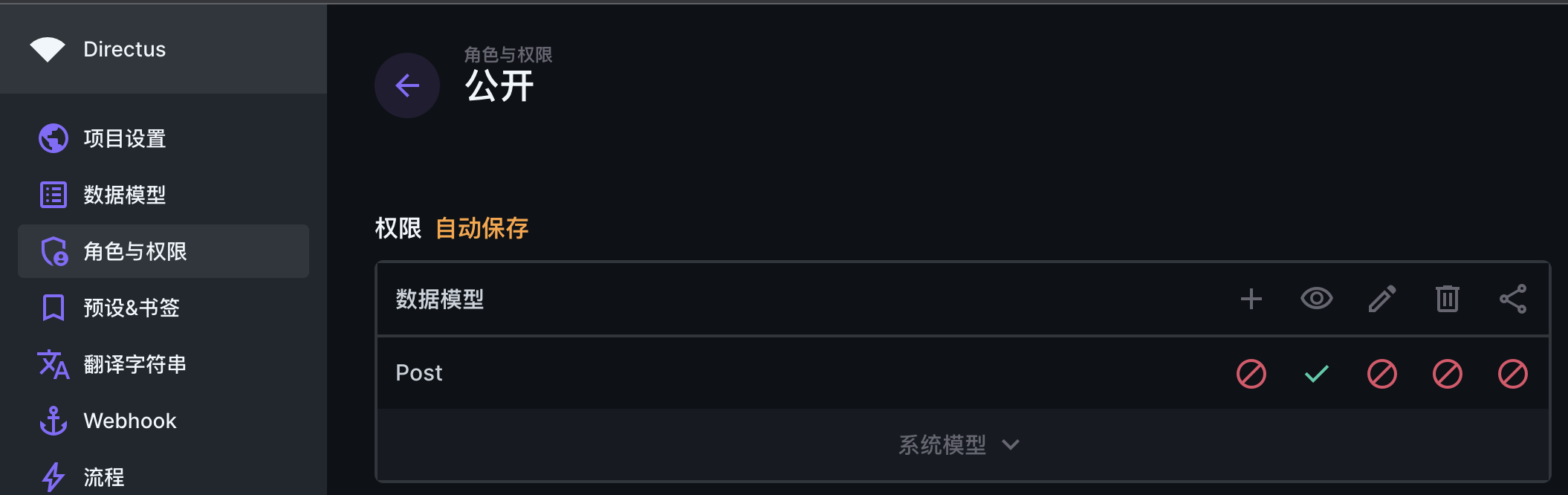
数据获取
管理界面中没有找到 restapi 的获取方式,需要从官方文档去找,去推测,比如刚才创建内容,访问的url 为,http://0.0.0.0:8055/items/post,需要处理好权限,如果做了权限访问,则需要更多的配置才能获取到数据。
返回的数据,是原始的标签,比如这种。
<p class="head1">我的第一篇文章来自directus,感谢你的支持。</p> <h1>我是标题</h1> <p><strong>我是重点内容</strong></p> <p><img src="http://0.0.0.0:8055/assets/1309183b-7289-474f-9251-2ee6edeab01e?width=3000&height=4497" alt="测试图片"></p>
其他
- 在线cloud,支持全球 CDN,看需要。
- 提供后台内容管理日志。
- 支持第三方云存储文件,支持 restapi 和 内置的 graphql api,版本管理、分享功能。
- 提供开发支持的 sdk,
npm install @directus/sdk - 功能比较多,开源版本不太友好,需要一定的摸索。
总结
- directus 功能最强大,不方便也更多。
- 没有提供更好展示端的模板,需要自己开发前端或者社区支持。
- 其他还有很多 headless cms,比如notion,ghost 等。形式上大同小异,无非就是数据的存储方式、存储地,功能上的差异等。